For my Operating Systems class CSCI360 we had to write the classic Producer-consumer problem in C using semaphores. This is a classic problem/solution to preventing race conditions over a shared resource. For those of you who don't know what a semaphore is it's simply a variable that acts as a counter ( with two operations up/down ) which puts a process to sleep if it tries to down/decrement a 0 valued semaphore. The process will receive a wakeup signal once the 0 valued semaphore is up/incremented by another process.
In the producer-consumer example below we have a critical region (the shared buffer) that needs to be controlled using semaphores to prevent race conditions. We create two semaphores one called EMPTY which represents the number of empty slots available for the producer and another semaphore called FULL to represent the number of slots occupied with items.
If there are no items in our buffer a consumer will goto sleep since it will try to down the FULL counter which will be 0 because there are no items occupying any slots for it to consume. Once the producer creates an item it will down EMPTY and up FULL; vice-versa. In the case of the consumer when it consumes items it will up EMPTY and down FULL. This might seem a little confusing at first so I created a diagram to illustrate the process (note: producer/consumer are NOT running in parallel in this diagram).
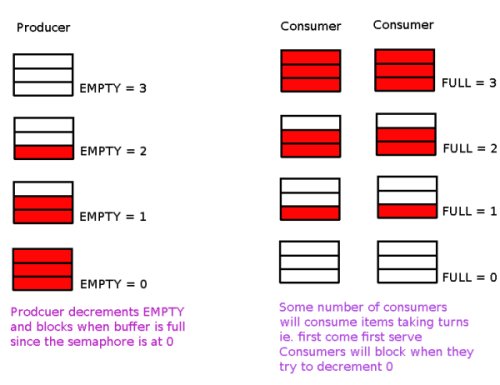
It is important to note that EMPTY and FULL alone do not prevent race conditions. This doesn't cover the case when the buffer is neither full nor empty. This means we need a third semaphore to lock the shared buffer to prevent consumers and producers from accessing the shared buffer at the same time. We call a semaphore with a single counter (initialized to 1) a binary semaphore or more commonly referred to as a mutex or lock. Using a mutex initialized to 1 when a consumer wishes to consume an item it simply needs to down the mutex before consuming the item which will prevent other producers/consumers from manipulating the shared buffer.
There are two main semaphore implementations in UNIX-based systems: System V (available in older-systems) and POSIX. For my example program I used System V implementation.
Producer
#include "shared.h"
void insert_item(int item, int semid, int *shared_buffer) {
int index = get_buffer_size(shared_buffer);
shared_buffer[index] = item;
}
int produce_item() {
return 0xFF; // nothing dynamic just write a static integer a slot
}
int main(int argc, const char *argv[])
{
int *shared_buffer = create_shared_mem_buffer();
int semid = create_semaphore_set();
clear_buffer(shared_buffer); // prepare buffer for jobs
int item = 0;
while(1) {
item = produce_item();
semop(semid, &downEmpty, 1);
semop(semid, &downMutex, 1);
insert_item(item, semid, shared_buffer);
debug_buffer(shared_buffer);
semop(semid, &upMutex, 1);
semop(semid, &upFull, 1);
}
return EXIT_SUCCESS;
}
Consumer
#include "shared.h"
void consume_item(int item) {
// do something with item
}
int remove_item(int semid, int *shared_buffer) {
int index = get_buffer_size(shared_buffer) - 1;
int item = shared_buffer[index];
shared_buffer[index] = 0x00;
return item;
}
int main(int argc, const char *argv[])
{
int *shared_buffer = create_shared_mem_buffer();
int semid = create_semaphore_set();
int item = 0;
while(1) {
semop(semid, &downFull, 1);
semop(semid, &downMutex, 1);
item = remove_item(semid, shared_buffer);
debug_buffer(shared_buffer);
semop(semid, &upMutex, 1);
semop(semid, &upEmpty, 1);
consume_item(item);
}
return EXIT_SUCCESS;
}
shared.h
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <sys/shm.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#define BUFFER_SIZE 5
#define EMPTY_ID 0
#define FULL_ID 1
#define MUTEX_ID 2
#define NSEM_SIZE 3
#define SHM_KEY 9
#define SEM_KEY "."
static struct sembuf downEmpty = { EMPTY_ID, -1, 0 };
static struct sembuf upEmpty = { EMPTY_ID, 1, 0 };
static struct sembuf upFull = { FULL_ID, 1, 0 };
static struct sembuf downFull = { FULL_ID, -1, 0 };
static struct sembuf downMutex = { MUTEX_ID, -1, 0 };
static struct sembuf upMutex = { MUTEX_ID, 1, 0 };
int *create_shared_mem_buffer();
int create_semaphore_set();
int get_buffer_size(int *sbuff);
void clear_buffer(int *sbuf);
shared.c
#include "shared.h"
/**
* returns current size of shared buffer
*/
int get_buffer_size(int *sbuff) {
int i = 0;
int counter = 0;
for (i = 0; i < BUFFER_SIZE; ++i) {
if (sbuff[i] == 0xFF) {
counter++;
}
}
return counter;
}
void debug_buffer(int *sbuff) {
int i = 0;
for (i = 0; i < BUFFER_SIZE; ++i) {
if (sbuff[i] == 0xFF) printf("1");
}
printf("\n");
}
/**
* returns a pointer to a shared memory buffer that the
* producer can write to.
*/
int *create_shared_mem_buffer() {
int *shmaddr = 0; /* buffer address */
key_t key = SHM_KEY; /* use key to access a shared memory segment */
int shmid = shmget(key, BUFFER_SIZE, IPC_CREAT | SHM_R | SHM_W); /* give create, read and write access */
if (errno > 0) {
perror("failed to create shared memory segment");
exit (EXIT_FAILURE);
}
shmaddr = (int*)shmat(shmid, NULL, 0);
if (errno > 0) {
perror ("failed to attach to shared memory segment");
exit (EXIT_FAILURE);
}
// clean out garbage memory in shared memory
return shmaddr;
}
/**
* only used in the producer to clean out garbage memory when
* constructing initial buffer.
*/
void clear_buffer(int *sbuff) {
int i = 0;
for (i = 0; i < BUFFER_SIZE; ++i) sbuff[i] = 0x00;
}
/**
* create FULL and EMPTY semaphores
*/
int create_semaphore_set() {
key_t key = ftok(SEM_KEY, 'E');
int semid = semget(key, NSEM_SIZE, 0600 | IPC_CREAT);
if (errno > 0) {
perror("failed to create semaphore array");
exit (EXIT_FAILURE);
}
semctl(semid, FULL_ID, SETVAL, 0);
if (errno > 0) {
perror("failed to set FULL semaphore");
exit (EXIT_FAILURE);
}
semctl(semid, EMPTY_ID, SETVAL, BUFFER_SIZE);
if (errno > 0) {
perror("failed to set EMPTY sempahore");
exit (EXIT_FAILURE);
}
semctl(semid, MUTEX_ID, SETVAL, 1);
if (errno > 0) {
perror("failed to create mutex");
}
return semid;
}